
I’ve been working with Hadoop for a few years now and the platform and ecosystems has been advancing at an amazing pace with new features and additional capabilities appearing almost on a daily basis. Some changes are small like better scheduling in Oozie; some are still progressing like support for NFS some are cool like full support for CPython in Pig but, in my opinion, the most important change is the introduction of YARN in Hadoop 2.0.
Hadoop was created with HDFS, a distributed file system, and Map/Reduce framework – a distributed processing platform. With YARN hadoop moves from being a distributed processing framework into a distributed operating system.
“operating system”, that sounded a little exaggerated when I wrote it, so just for fun, I picked up a copy of Tanenbaum’s “Modern Operating Systems”*, I have lying around from my days as a student – Tanenbaum says there are two views for what an OS is:
- A virtual machine – “…the function of the operating system is to present the user with the equivalent of an extended machine or virtual machine that is easier to program that the underlying hardware”
- A resource manager “… the job of the operating system is to provide for an orderly and controlled allocation of the processors, memories, and I/Odevices among the various programs competing for them”
Hadoop already had the first part nailed down in its 1.0 release (actually almost from its inception). With YARN it gets the second – so, again, in my opinion Hadoop now can be considered a distributed operating system.
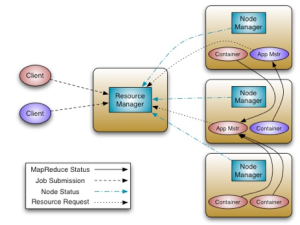
So, YARN is hadoop resource manager, but what does that mean. Well, previous versions of Hadoop were built around map/reduce (there were few attempts at providing more computation paradigms but m/r was the main and almost only choice). The map/reduce framework, in the form of the jobtracker and tasktracker handled both the division of work as well as managing the resources of the servers – in the form of map and reduce slots that each node was configured to have.
With Hadoop 2.0, the realisation that map/reduce, while great for some use cases, is not the only game in town, led to a better, more flexible, design that separates the responsibility of handling the computational resources from running anything, like map/reduce, on these resources. YARN, as mentioned above, is that new resource manager.
There’s a lot more to say about YARN, of course, and I highly recommend reading HortonWorks’ Arun Murthy’s excellent series of posts introducing it.
What I do want to emphasis is the effect that this separation already has on Hadoop eco-system, here are a few samples
- Storm on Yarn – Twitter’s streaming framework made to run on Hadoop (Yahoo)
- Apache Samza – a Storm alternative developed from the ground up on YARN (Apache)
- HOYA – HBase on Yarn, enabling on the fly clusters (Hortonworks)
- Weave – a wrapper around YARN to simplify deploying applications on it (Continuuity)
- Giraph – a graph processing system (Apache)
- LLama – a framework to allow external servers to get resources form Yarn – (Cloudera)
- Spark on Yarn – Spark is an in-memory cluster for analytics
- Tez – a generalization of map/reduce to any directly acyclic graph of tasks (HortonWorks)
- etc.
In summary – in my opinion, the introduction of YARN into the Hadoop stack is a game changer – and it isn’t some theoretic thing that would happen in the distance future – Hadoop 2.0 is now GA , so it is all right here, right now…
illustration by Elizabeth Moreau Nicolai on Born Librarian
*- ok, so I have an earlier edition than that :)


as platform and ecosystems has been advancing Google also working hard to processing bigData fastly
Google publish Google Dremel paper and Apache drill is in progress.
After Hadoop , Aache drill will be next Hot Tech in BigData
what you think ?
There are a lot of efforts to bring SQL on Hadoop (see https://arnon.me/2013/07/nosql-resql/) but I am not sure drill will be the one prevailing there (Cloudera, HotronWorks etc. are all looking elsewhere). Also SQL is one hot area around Hadoop another is the whole streaming/real-time and I technologies around that would be ore important – after all we already have RDBMs that do SQL very well and streaming is more of a differentiator to bring insights when they are needed based on fresh data